In 1943, psychologist Abraham Maslow first introduced his concept of a hierarchy of needs in his paper “A Theory of Human Motivation.” This hierarchy suggested that people are motivated to fulfill basic needs before moving on to other, more advanced needs.
Maslow’s hierarchy is most often displayed as a pyramid. The lowest levels of the pyramid made up of the most basic needs, while the most complex needs are at the top of the pyramid. Everyone is capable and has the desire to move up the hierarchy toward a level of self-actualization. Unfortunately, progress is often disrupted by failure to meet lower level needs.
Similar to Maslow’s hierarchy, data science advisor Monica Rogati has developed a similar pyramid to illustrate that while most firms are striving for the top of the data science hierarchy of needs (artificial intelligence), many more basic requirements must first be met. This is a great visual for the banking industry, where data seems abundant, but the ability to process and apply this data is less assured.
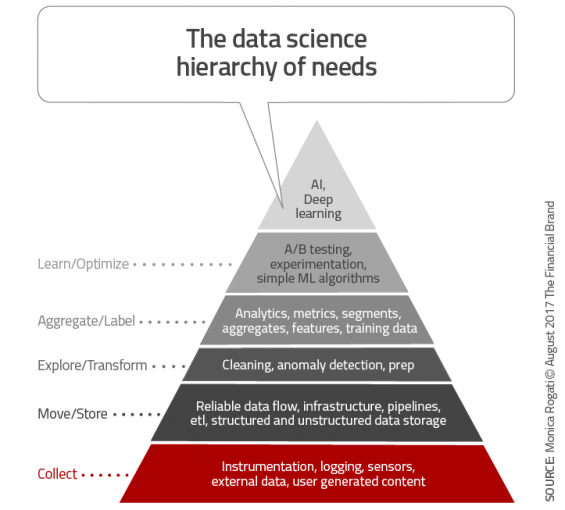
Begin With a Strong Foundation
The largest and most basic need in the data science hierarchy is the need for data collection. While every bank and credit union collects data daily on transactions, product use, customer demographics, and even external insights from social media and other sources, an organization needs to determine what specific insight may be needed to get a complete picture.
Are you collecting insight on channel use, geolocational data and consumer beliefs and behaviors? While you can build a plan for future collection, the success of any machine learning or AI initiative hinges on the scope and quality of data collected.
As important as the collection of the right data is important, Rogati stresses that it is equally important to have an ongoing flow of real-time data that is easy to access, store and analyze. This can be a major challenge for financial services organizations that are notorious for having data silos. Beyond internal data flows, it is important that any external or unstructured data can also be collected, stored and analyzed. While once a major problem, cloud technology has simplified some of the storage challenges.
Garbage In, Garbage Out
As with any data collection and analysis exercise, the result of your data work is only as good as the data used to get to the pinnacle. The third stage of the hierarchy is the step where you explore and transform data. This includes data cleansing, as well as digging deep into the data to ensure you have all of the data needed to reach your ultimate goal.
Are your sources reliable and cadence consistent? Are you missing data and insights that could impact your final results? Remember, in many cases, the application of your AI and deep learning will be to improve the customer’s banking experience, provide proactive financial recommendations and/or be applied to fraud and risk avoidance. Errors at this stage can be costly. Always test to make sure the foundation of your data pyramid remains strong.
Transforming Data Into Insights
Transforming data into insights is the highest stage that many financial services organizations ever reach in the data pyramid. Data is collected from many sources, cleansed, and turned into valuable reports that are used internally to measure performance.
Unfortunately, these insights are never used to create valuable customer experiences. Why go through all of the effort to collect and analyze customer insights and not use this insight for segmentation, product development, offer selection, etc.
For those organizations that want to proceed to the level of AI and machine learning, the stage of aggregation and labeling is simply a ‘rest stop’ in the journey. This is the stage where you determine what you ultimately want to predict or learn and what components of the insight will help you reach your goal.
Learn and Optimize
It is far easier (and less risky) if a bank or credit union wants to use data insights for internal purposes. Analyzing customer acquisition, attrition, product utilization and cross-selling for department managers has less risk than using this same analysis to communicate with the customer.
During this learn and optimize stage, Rogati states, “We need to have a (however primitive) A/B testing or experimentation framework in place, so we can deploy incrementally to avoid disasters and get a rough estimate of the effects of the changes before they affect everybody.” Rogati also stresses the need for establishing a baseline to measure results against.
Simple machine learning algorithms like logistic regression are also recommended at this stage to ensure all needed insights are included in the dataset. Again, time spent on this stage will reduce challenges and improve results down the road.
AI and Machine Learning
There is no guarantee that machine learning and AI will improve your results. Similar to a turbocharged car with bad wheel alignment or bad breaks, the most advanced data analytics tools may simply get you to the wrong outcome faster. But if you are collecting the needed real-time data, that is organized, clean, tested and optimized, it is time to test machine learning and artificial intelligence solutions.
The final solution may be home grown or outsourced. Either way, it is far from a hands-off process. The human component is important at every stage. The knowledge of the data and the interrelationship of data is invaluable as you try to build advanced analytic solutions.
Remember, in the end, if the foundation is weak (dirty, incomplete data), the solution will not be optimized. In fact, the final result could be completely off track. Rather than skipping steps or not fighting the needed internal battles, make sure the foundation is as strong as possible. Even if you don’t reach the highest level of the data pyramid, your organization will benefit from the application of data and analytics for more modest solutions.